I've decided to give up on supporting 3.0 (trying to support two different broken versions of code is not fun), so the oldest supported version is now listed as 3.1 beta 2. In reality, it would work with any nightly since the broken code was fixed (it's still not fully fixed now, but it's just a cosmetic issue). The result is an experimental addon on addons.mozilla.org. For those of you dying for screenshots, this page on mozdev should satiate you.
Tuesday, April 27, 2010
A new folder tree view for real
Seeing as how the first build candidates of Thunderbird 3.1 beta 2 are currently being spun, it is time for me to update from the 3.0 builds to 3.1 builds (I have a policy of switching to the next branch of Thunderbird as my primary at the time of the last beta). I decided to take this opportunity to work out issues in my folder categories extension for real.
Sunday, April 11, 2010
Animated code coverage
I recently spent a fair amount of time collecting historical code coverage data for Thunderbird; the result is 312 distinct files of raw lcov data covering the first year of Thunderbird in a mercurial repository. I also recently wrote a program that makes a treemap for each day (thanks to the geninfo man page and this treemap library), and then wrote another program to convert that treemap into a static PNG image:
view.setSize(1920,1080); BufferedImage image = new BufferedImage(view.getWidth(), view.getHeight(), BufferedImage.TYPE_INT_RGB); view.paint(image.getGraphics()); ImageIO.write(image, "png", new File(args[1])); System.exit(0);
I ran that tool to create images for every single day, and then I made another short script to add dates to each of the images (ImageMagick works really well here):
DATE=$(echo $1 | cut -d'.' -f1) convert -fill "#aaa" -pointsize 50 label:"$DATE" /tmp/label.png composite -compose Multiply -gravity southwest /tmp/label.png $1 anno-$1
Now, with 312 images on hand, I decided to make them into a video:
mencoder mf://out/anno-*.png -mf w=1920:h=1080 -ovc lavc -lavcopts vcodec=ffv1 -of avi -ofps 3 -o output.avi
I then converted the high-def, lossless AVI into an Ogg file, and produced the following animated video of historical code coverage:
Okay, so no sound yet for the animation—the encoding is painful enough that I don't want to try it out right now. I also didn't filter out any of the days where the tests failed early, so you will occasionally see flashes of red. The data also doesn't have recent stuff (I am holding off until I can figure out how to run mozmill tests and get JS code coverage). Anyways, enjoy!
Sunday, April 4, 2010
Developing new account types, Part 2: Message lists
This series of blog posts discusses the creation of a new account type implemented in JavaScript. Over the course of these blogs, I use the development of my Web Forums extension to
explain the necessary actions in creating new account types. I hope to add a new post once every two weeks (I cannot guarantee it, though).
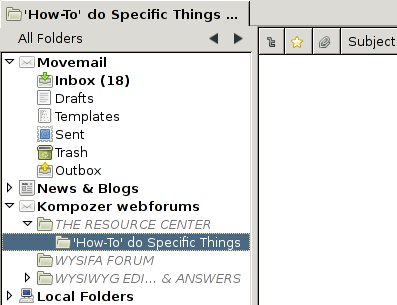
In the previous blog post, I showed how to get an account displayed in the folder pane. Now, we will prepare the necessary components of getting an empty message list displayed in the folder pane.
Database basics
As mentioned previously, the database is one of the key components of an account. It is, essentially, the object that actually stores the state of messages in folders and even some folder attributes themselves. The database is currently backed by a mork database (the .msf files you see in your profile storage); in principle, you could make your own database from scratch that doesn't use mork, but that is likely a very bad idea. [1]
Originally, as I understand it, the database was merely a cache of the data in the actual mailbox. Its purpose was to store the data that was needed to drive the user interface to prevent having to reparse the potentially large mailbox every time you opened up Netscape. The implicit assumption here was that blowing away the database was more or less lossless. Well, times change, and now such actions are no longer lossless: pretty much any per-folder or finer-grained property is stored in the message database; in many cases, these properties are not stored elsewhere.
The database itself is represented by the nsIMsgDatabase interface. Messages and threads are represented by the nsIMsgDBHdr and nsIMsgThread interfaces, respectively. Per-folder property stores are represented by nsIDBFolderInfo. Finally, the code to open a new database comes from nsIMsgDBService. Most of the database stuff just works; subclasses would implement only a few methods to override the default ones.
Getting databases
There are two main entry points for getting databases: msgDatabase, and getDBFolderInfoAndDB. Both of these must be implemented for anything to work:
wfFolder.prototype = { getDatabase: function () { if (this._inner["#mDatabase"]) return this._inner["#mDatabase"]; let dbService = Cc["@mozilla.org/msgDatabase/msgDBService;1"] .getService(Ci.nsIMsgDBService); let db; try { db = dbService.openFolderDB(this._inner, false); } catch (e) { db = dbService.createNewDB(this._inner); } this._inner["#mDatabase"] = db; return db; }, getDBFolderInfoAndDB: function (folderInfo) { let db = this.getDatabase(); folderInfo.value = db.dBFolderInfo; return db; }, };
This portion of the code can turn out to be surprisingly complicated. What is listed is generally a safe option: if the database is incorrect (out of date or non-existent), blow away the database and re-retrieve the information from other sources. Recreating the database is done in the catch statement. Then we set the member variable to be the newly-created database (this is also used by nsMsgDBFolder code) and we return it. Retrieving the folder info should be self-explanatory.
You may notice that when the database is invalid, all we do is create a new database: we don't try to fix it. This is because these calls to get the database are interested in getting a version of the database quickly: this is one of the calls the folder pane makes, and it is synchronous. Imagine what would happen if, say, a local folder which had a 3GiB backing store needed to be reparsed during this call. The actual recovery of the database would most likely happen when the folder is told to update.
Other stuff can be added to these calls. Not everything is necessarily stored in the database: news folders store their read information in the newsrc file, so it needs to sync this with the database in the method too.
Displaying an empty message list
If you just try to implement this code and run, you will discover that this is not sufficient to load the database. The key is in the getIncomingServerType function, which is what tells the database service which implementation of nsIMsgDatabase to use. For now, we can just use the default implementation of nsMsgDatabase, but we can't change the parameter output (otherwise URIs will get messed up). The solution is to create a DB proxy:
function wfDatabase() {} wfDatabase.prototype = { contractID: "@mozilla.org/nsMsgDatabase/msgDB-webforum", _xpcom_factory: { createInstance: function (outer, iid) { if (outer) throw Cr.NS_ERROR_NO_AGGREGATION; return Cc["@mozilla.org/nsMsgDatabase/msgDB-default"].createInstance(iid); } } };
What this does is use some XPCOM magic to link creating one contract ID to creating the other. I have not yet used the extend-C++-in-JS glue to create the ability to subclass nsMsgDatabase due to the fact that the nsIMsgDatabase interface is more complicated than the others, as well as it being more C++-specific codewise and generally less useful to override methods.
The next thing to do to display the list is to write a simple no-op implementation for updateFolder (the default implementation doesn't do this, for some reason [2]):
updateFolder: function (msgwindow) { this._inner.NotifyFolderEvent(atoms["FolderLoaded"]); }
Here, atoms is merely is an associative array that contains a list of necessary atoms for the code. The end result of all of these changes is the following screenshot:
In the next part, I'll cover how to replace that screenshot with one containing an actual folder list.
Notes
- As annoying as it would be, implementing nsIMsgIncomingServer or nsIMsgFolder from scratch is still somewhat feasible. I don't think the same holds true for nsIMsgDatabase (or the other database helper interfaces): static_casts permeate the code here, with the note that it is a "closed system, cast ok".
- If you're wondering why this post took so long to be produced, this is a major reason why. It turns out that not having this implementation causes the folder display to not display the database load, so it just displayed the server page with the server name changed to the folder name. That, on top of having no time to debug it.
Friday, April 2, 2010
Code coverage to the extreme
If all goes well, sometime tonight I will have completed 362 builds of Thunderbird, one for each day from July 24, 2008 to July 23, 2009 excluding August 3, 2008, December 25, 2008, and July 4, 2009 (more may turn up as I get more data; bonus points if you can figure out the significance of each of those days!). Included for each build is either a build log to tell me why the build failed or a test log telling me what ran. Also included is a copy of the Thunderbird code coverage data.
What, you may ask, do I intend to do with a year's worth of code coverage data? I intend to use this data to help answer some questions I have about our code coverage. Already, I've wondered about a more general overview of code coverage data (see my last post for more details). Now, I want to pose some of the following questions:
- Whose code is not covered?
- Who is adding code right now without making sure to cover it?
- Whose tests are responsible for most improving code coverage?
- How is code coverage being impacted over time?
My answers to these questions involves taking a snapshot of the code coverage data over time. That, however, proves to be a little more difficult than you'd imagine. First of all, hg doesn't support, as far as I can tell, an "update to what the repo looked like at this time" (hg up -d goes to the revision that most matches that date, not to a snapshot at that time). So I had to write a few scripts to pull out the revisions to look at. Second, gloda ruined some of this data. Fortunately, that's easy to tell due to the <1KB log files complaining about no client.mk. Then there's the issue of my revision logs containing m-c data, not m-1.9.1, so I have to hack around the client.py for Thunderbird trying to pull a different revision.
Another source of complaints was actually building and running the things. The computers I'm doing this on are all 64-bit Linux. There are a few m-c revisions that cause 64-bit to break, and libthebes and gcov just can't seem to work together on 64-bit Linux. Plus, libpango has some breaking API changes between 2.22 and 2.24. One of the XPCOM tests seems to crash and sit there with a prompt saying "Do you want to debug me?" Finally, the test plugins seem to cause massive test failure due to assertions. Not to mention that these machines don't have lcov on them and I don't have sudo privileges (so I'm not running mozmill tests yet).
In short, it's somewhat surprising to me that this actually works. Just looking at some of the build generation shows some coarse changes: between October 2008 and June 2009, the size of the compressed test log files increase 6-fold, and the compressed lcov output has nearly doubled in the same period. Lcov also reported that the coverage increased from about 20% to around 40% as well.
Sometime later, I'll hope to get mozmill tests working, as well as improving the JS code coverage to actually work for Thunderbird (it doesn't like E4X nor some of the other files for no apparent reason). Since jscoverage works by modifying the JS code, I can run that without really needing the builds (archived nightlies plus tricking the build-system will work). When all that data is collected, or sometime before, I'll make a nice little web-app that shows all of this information so people can gawp at pretty pictures.
If you want to try this on your own, here is the shell script I used to actually collect data:
#!/bin/bash
if [ -z $1 ]; then
echo "Need a date to build"
exit 1
fi
DATE=$1
REV=$(grep $DATE comm-revs.log | cut -d' ' -f 3)
MOZREV=$(grep $DATE moz-revs.log | cut -d' ' -f 3)
if [ -z $REV -o -z $MOZREV ]; then
echo "Illegal date"
exit 2
fi
echo "Updating to $REV"
hg -R src update -r "$REV"
hg -R src/mozilla update -r "$MOZREV"
pushd src
python client.py --skip-comm --skip-mozilla checkout &> ../config-$REV.log
make -f client.mk configure &> ../config-$REV.log
popd
pushd obj/mozilla
#make -C .. clean &>/dev/null
for f in $(ls config/autoconf.mk nsprpub/config/autoconf.mk js/src/config/autoconf.mk); do
sed -e 's/-fprofile-arcs -ftest-coverage//' -e 's/-lgcov//' -i $f
done
echo "Building mozilla..."
make -j3 &> ../../build-$REV.log
popd
pushd src
echo "Building comm-central..."
make -f client.mk build &> ../build-$REV.log || exit
popd
LCOV=lcov-1.8/bin/lcov
$LCOV -z -d obj
pushd obj/
echo "Running tests..."
rm -f mozilla/dist/bin/plugins/*
make -k check &>../tests-$REV.log
make -k xpcshell-tests 2>&1 >>../tests-$REV.log
popd
$LCOV -c -d obj -o $REV.info
echo 'Done!'
Don't bother complaining to me if it doesn't work for you. I just did what I needed to do to get it to reliably work. And be prepared to wait for a few hours to collect any non-trivial number of builds. It took me about 12 hours to get 6 months worth of data using 6 different computers; the next 6 months is still going on right now.
Subscribe to:
Posts (Atom)